# 정보의 최소 단위
사람은 숫자를 다룰 때 10을 기수로 하는 십진법을 사용하고
컴퓨터는 0과 1을 이용하는 이진법을 사용합니다.
컴퓨터는 논리 회로를 통해 연산하는데 논리 회로는 전기 신호를 구분합니다.
신호가 있으면 1, 없으면 0으로 처리하기 때문에
컴퓨터는 0과 1만 사용하는 이진법을 사용합니다.
컴퓨터가 처리할 수 있는 가장 작은 단위를 비트(bit)라고 하는데
이진수를 의미하는 'Binary Digit'의 약자입니다.
비트에는 있고 없음을 나타내는 0과 1만 담을 수 있습니다.
1bit는 0과 1, 두 가지를 표현할 수 있고
2bit는 00, 01, 10, 11 총 네 가지의 경우를 나타낼 수 있습니다.
비트가 늘어날 때마다 ×2 만큼 경우의 수가 증가합니다.

1bit로 많은 데이터를 나타낼 수 없어서 컴퓨터는 정보를 표현하는 기본단위로 1byte를 사용합니다.
바이트(byte)는 여덟 개의 비트로 구성된 데이터의 양을 나타내는 단위이고
총 256개의 정보를 나타낼 수 있습니다.
# 10진수를 2진수로 변환하기
사람에게 익숙한 10진법을 컴퓨터는 사용하지 못하기 때문에 변환해야 합니다.
10진수를 2진수로 변환하는 방법은 2로 나눌 수 없을 때까지 나누고 나머지를 뒤집으면 됩니다.
이해를 돕기 위해 예시로 숫자 17을 2진수로 변환하겠습니다.
17을 2로 나누면 몫은 8 나머지는 1, 8을 2로 나누면 몫은 4 나머지는 0, ...
더 이상 2로 나눌 수 없을 때 그동안 나왔던 나머지를 뒤집으면 17의 2진수가 됩니다.
# 2진수를 10진수로 변환하기
2진수를 10진수로 변환하는 방법은 비트의 위치에 맞게 2의 제곱 값을 계산해서 변환하면 됩니다.
# 인코딩, 문자 인코딩과 문자 집합
인코딩이란 정해진 규칙에 따라 변환하는 것을 말합니다.
컴퓨터는 정보를 처리할 때 바이너리(이진법) 형태로 저장하기 때문에
사람이 사용하는 정보들을 그대로 사용할 수 없고,
사람도 바이너리 형태를 그대로 사용하는 것이 힘들기 때문에
컴퓨터가 이해할 수 있도록 정보들을 바이너리 형태로 인코딩해야 합니다.
10진수를 2진수로 변환하는 것처럼 문자도 인코딩해야 합니다.
문자마다 숫자를 지정하고 그 숫자를 바이너리 형태로 변환합니다.
대문자 A는 65로 정하고, 65를 1000001로 전환시킵니다. ( A → 65 → 1000001 )
사람의 문자를 바이너리 형태로 바꾸는 것을 문자 인코딩,
문자를 바이너리로 표현하기 위해 문자를 숫자에 매칭시킨 것을 문자 집합(Character Set)이라고 합니다.
# 문자열 깨짐 현상

웹에서 가끔 문자열들이 알아볼 수 없게 깨져서 출력되는 경우가 있는데
그건 인코딩 방식이 달라서 발생하는 문제입니다.
기본적으론 UTF-8 인코딩 방식을 사용하는데 그것과 다른 방식으로 인코딩을 하게 되면 문자열이 깨져서 출력됩니다.
다양한 문자 인코딩 방식이 존재하고, 문자 집합의 구성 또한 모두 다릅니다.
다른 문자 집합끼리 호환되지 않기 때문에 문자열이 깨지거나 이상한 글자로 출력됩니다.
# 문자 인코딩
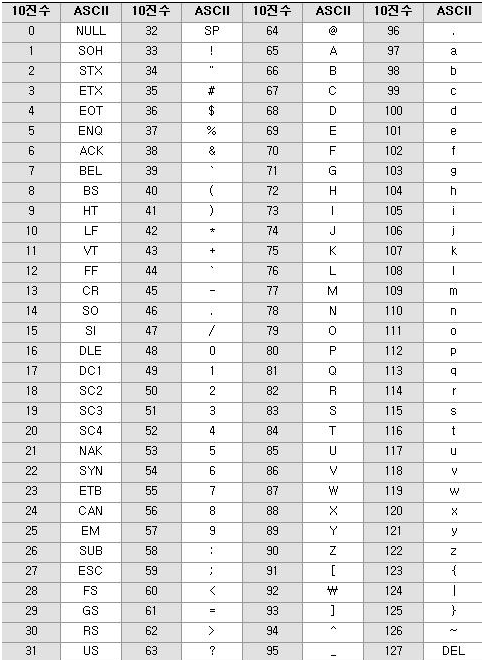
최초로 나온 문자 인코딩은 ASCII (American Standard Code for Information Interchange)입니다.
영문 알파벳 26자와 숫자, 기호, 특수문자 등 128자를 7비트의 고정길이로 표현합니다.
아스키는 영문자를 위해 만들어진 인코딩이기 때문에 다른 문자는 표현이 불가능합니다.
우리나라도 한글을 표현하기 위해 문자 집합을 만들려고 하는데
한글은 영어, 중국어처럼 나열해서 사용하는 글자가 아닌 문자를 조합해서 사용하는 글자이기 때문에
어떤 식으로 인코딩할지 두 가지 의견이 있었습니다.
문자를 초성, 중성, 종성으로 분리해서 각각 인코딩하자는 의견과
완성된 문자를 인코딩하자는 의견이 있었습니다.
조합형을 사용하면 자음과 모음의 모든 조합을 표현할 수 있지만
하나하나 조합해서 글자를 만들어야 하기 때문에 효율이 떨어지는 단점이 있습니다.
완성형은 문자를 해독할 때 들어가는 부하를 줄일 수 있는 장점이 있고
문자 집합에 없는 문자를 표현할 수 없다는 단점이 있습니다.
그러다가 EUC-KR (Extended Unix Code-Korea), CP949(MS949) 같은 완성형 한글 인코딩 방식을 사용합니다.
(n바이트 조합형, 3바이트 조합형, 2바이트 조합형 같은 조합형 인코딩 방식을 사용하는 생김)
하지만 문자 집합을 만들어도 문자 집합 안에 있는 제한적인 글자들만 표현이 가능하고,
다른 나라의 문자도 표현해야 하는데 그 나라마다 사용하는 국가별 표준 문자 집합을 사용해서 인코딩해야 했습니다.
불편함을 감수하고 그렇게 인코딩을 한다 해도 다른 문자 집합끼리는 호환되지 않기 때문에
한 곳에 여러 개의 문자를 표현하는 것이 불가능했습니다.
다른 문자 집합끼리 호환되지 않는 이유 (EUC-KR과 UTF-8 비교)
'인코딩'이라는 문자열을 두 가지 방식으로 인코딩
# EUC-KR
→ 한글 한 글자 2바이트
<16진수>
인: C0CE, 코: C4DA, 딩: B5F9
<2진수>
인: 1100000011001110, 코: 1100010011011010, 딩: 1011010111111001
# UTF-8
→ 한글 한 글자 3바이트
<유니코드 16진수>
인: C778, 코: CF54, 딩: B529
<유니코드 2진수>
인: 1100011101111000, 코: 1100111101010100, 딩: 1011010100101001
UTF-8은 { U+0800 ~ U+FFFF } 범위는 첫 바이트는 1110으로 시작하고 나머지 바이트들은 10으로 시작함
→ 1110xxxx 10xxxxxx 10xxxxxx
x 위치에 유니코드 2진수 값을 넣으면
인: 11101100 10011101 10111000 / EC9DB8
코: 11101100 10111101 10010100 / ECBD94
딩: 11101011 10010100 10101001 / EB94A9
같은 문자열을 인코딩해도 인코딩 방식에 따라 내용이 달라집니다.
EUC-KR : 110000001100111011000100110110101011010111111001
UTF-8 : 111011001001110110111000111011001011110110010100111010111001010010101001
# 유니코드
모든 국가가 같은 문제를 겪었고 문제를 해결하기 위해 모든 나라에서 사용되는 문자를 포함하는
새로운 문자 집합을 만들었습니다.
그 문자 집합이 유니코드입니다.
유니코드는 완성형 인코딩 방식으로 현재 국제 표준 문자집합으로 사용되고 있습니다.
# 유니코드 인코딩 방식
유니코드는 아스키 코드처럼 문자 집합을 그대로 사용하는 것이 아니라 문자 집합을 다시 인코딩해야 합니다.
유니코드를 인코딩하는 방식에는 UCS_2, UTF-8, UTF-16, UTF-32, 등이 있습니다.
문자마다 적절한 바이트 수를 차지해서 다른 방식들보다 적은 용량을 사용하면서 호환 문제도 가장 적게 발생하는
UTF-8이 국제적으로 많이 사용되고 있습니다.
UTF-8은 길이가 정해져 있지 않고 필요에 의해 길어질 수 있는 가변 길이 인코딩 방식입니다.
UTF-16 역시 가변 길이 인코딩 방식이지만 기본적으로 2바이트를 사용하고 있어서
ASCII처럼 1바이트로 표현할 수 있는 문자도 2바이트를 소모하게 합니다.
그래서 UTF-16보다 UTF-8이 많이 쓰이고 있습니다.
